Google Cache Browser 3.0: The Late Announcement

Today I’m going to announce a pet project, which I’ve been working on for a last few month. It happened so that it’s live for more than two years and it’s the third major release, but I never announced it on my blog. Now I have to fix this.
Meet: Google Cache Browser.
The idea behind this project is pretty simple: when viewing Google’s search cache, click on any link on the cached page is going to send you back to live site, not to cache, and there are many situations when this is not what you want. For example, when you site of interest is under maintenance and you need to find something there, all internal links would be broken, leading you to “Temporary unavailable” page.
This is where Google Cache Browser comes in. It would inject himself into cached page, catch all click on links and redirect you to cached versions of paged they point to. The most beautiful thing is that you don’t have to install any kind of browser extensions: GCB is a pure JavaScript running is your browser.
There are two ways to use GCB:
- Open cache.nevkontakte.com, put in URL of a page and hit “Go”.
- Use GCB bookmarklet. It’s designed to take you to the cached version of page you’re currently viewing, plus adding all nice GCB features.
History
As I said, the service already has been live for a while and now what you see is third version. What were two previous ones?
2008: The First Version
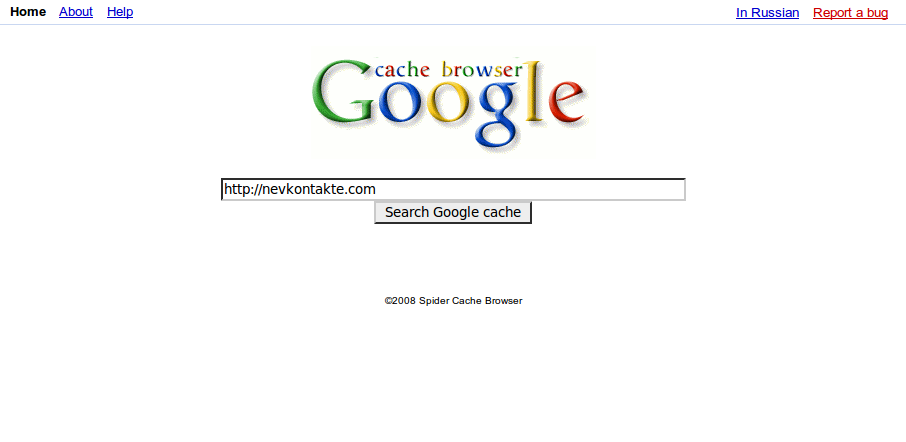
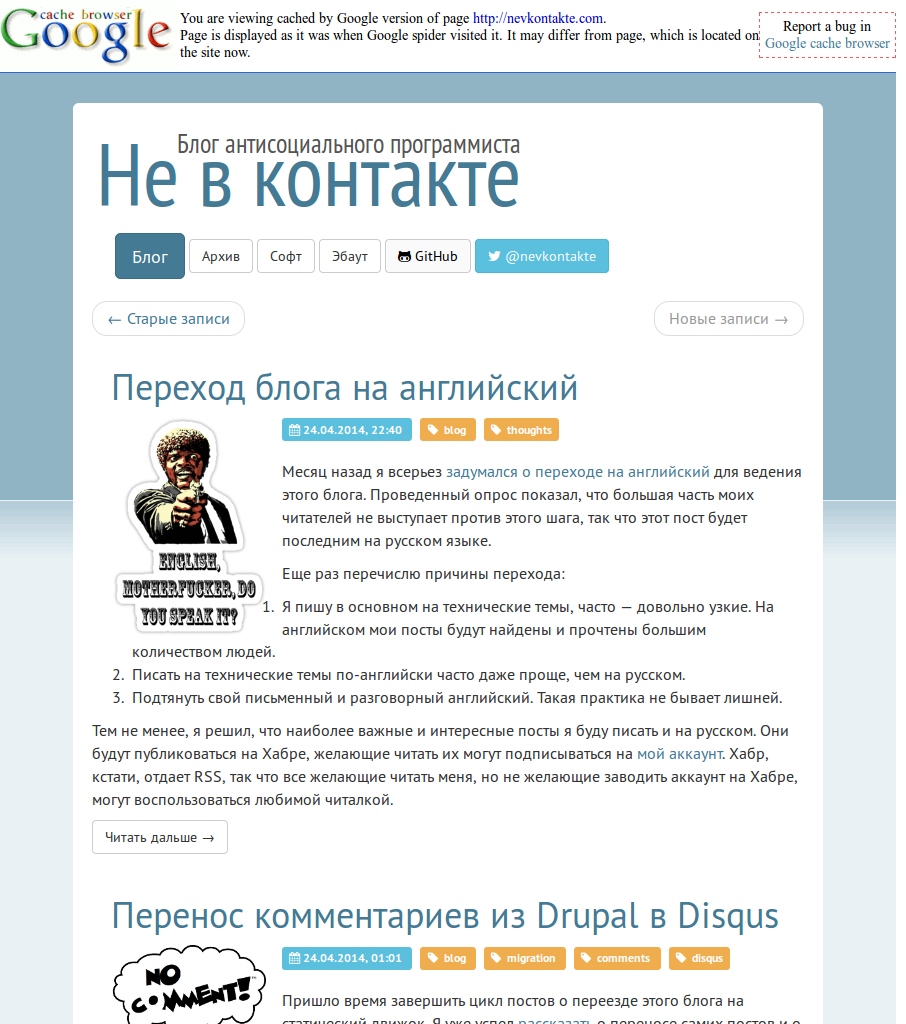
When I had created the first version back in 2008, it was quite simple PHP script. It ran on my hosting and acted like a proxy between user and Google’s cache. It used regexp to find links in page body and replace them with special URLs pointing back to GCB.
Though it did the job, there were a lot of problems. First, it got banned by Google’s anti-abuse filters pretty regularly. Second, you can’t event imagine how bad HTML could be. Thus regexps inside became more and more complicated and slow and still there were cases not covered by them. Finally, it couldn’t do anything about links dynamically created with JS.
As a result, I abandoned this script and removed to from hosting somewhere in 2010. But I’ve managed to find sources in archives to share few screenshots:
2012: The JavaScript Rebirth
It was an winter exams time, when I found myself totally bored by math and looking for some fun with coding. Eventually, I decided to recover my old GCB service but with it’s problems fixed. I thought that it would be awesome, it all magic happened on client side. Really, browser would do his job parsing dirty HTML, Google wouldn’t complain about suspicious requests from my server’s IP, everybody would be happy and celebrating.
There was only one problem between me and The Bright Future®: same-origin policy. No scripts running on my domain could interfere with contents of pages on Google’s domains. Luckily, I’ve found out that cached pages still fetch all resources including scripts from original hosts, which allowed me to inject my code into Google’s cache domain.
It took me several evenings to come up with working version:


I was satisfied by this result and announced it at HabraHabr.
Anyway, there were some imperfections:
- Poor design. I never was a great designer, so this version 100% looked like “designed by engineer”.
- It had to wait until browser completely loads a page to hook all links.
- It still might miss some JS-generated links, which might appeared after page was completely loaded.
So, after taking a brake, I returned to…
2013–now: JavaScript-Fu and Magic
At some point I realized that I’m getting bored again. And I new the solution: rewrite GCB! :-)
So I found Bootplus (googly-looking Twitter Bootstrap fork), added some Can.js and re-engineered page loading engine. And also I’ve added bookmark support I’ve mentioned earlier. Now it was able to hook link on-the-fly, load pages faster with lesser load on CPU, catch all dynamically created links and looked flat and modern. Among other nice features I’ve integrated UserVoice form for feedback and bug reports.
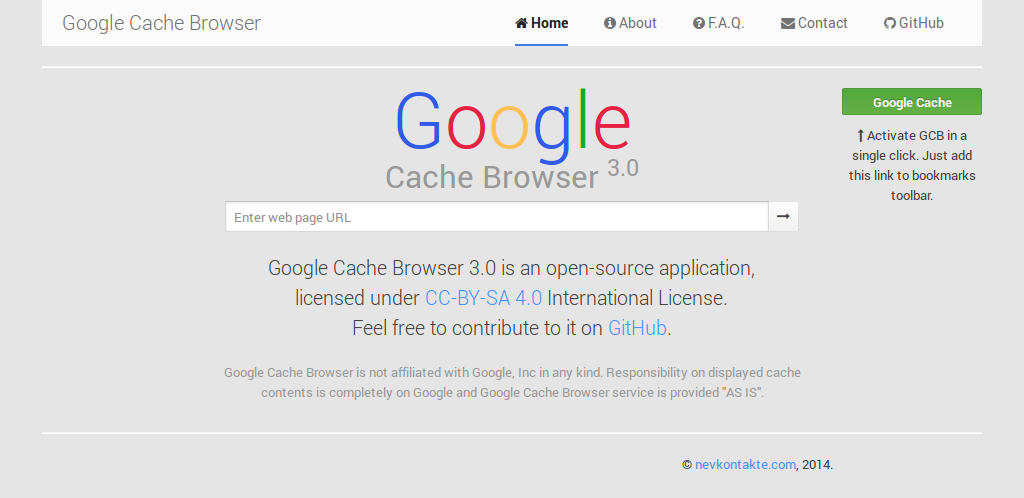
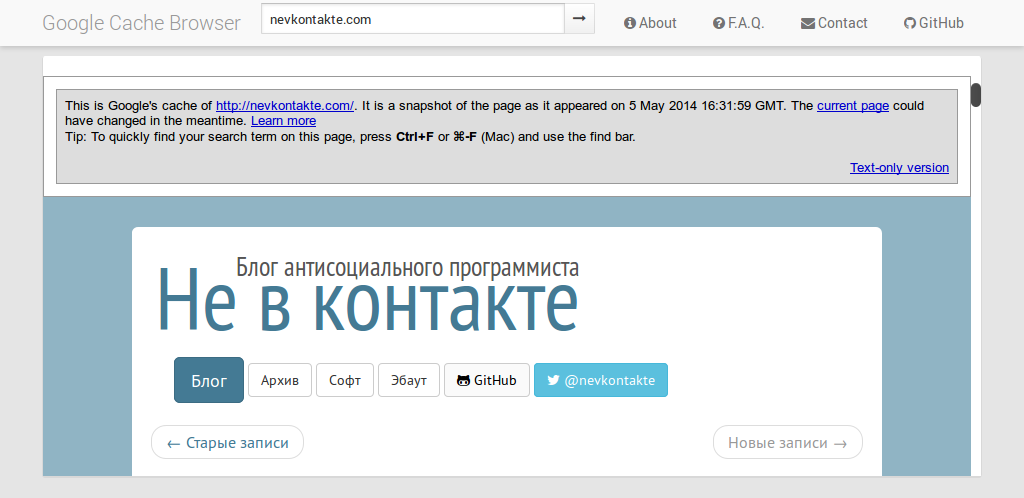
And here comes her majesty Fortune. I never advertised GCB after 2.0 release (frankly, I was lazy, and promoting is boring), but soon after 3.0 there strong flow of visitor appeared. And it took only two month to eat my hosting traffic quota making unavailable GCB, this blog and few other sites I host. So I had to move fast and host the service on GitHub Pages, implementing 100% automated deployment with TravisCI (consider this as announcement of next post). This allowed me to offload this from my hosting and even improve page loading time =)
Future Plans
Now GCB seems to enter self-sustaining phase. It works well in all modern
browsers (an even in mammoth shit old ones like IE8), it costs me nothing
and makes this world a better place. It still has some
issued and features to be implemented
and I return to them from time to time.
If you’d like to help, feel free sending me pull requests. Or you might want to make GCB more reliable by hosting copy of it’s backend on your site. And feedback is appreciated at any time! =)